
Incompetent or deceptive?
Incompetent or deceptive?
When someone makes errors that tend to be in support of their position, how long before we think the errors are deliberate and deceptive?

People making a point sometimes make errors; can we trust errors that help their point to be accidental?
The answer to that must depend on the total number of errors and the fraction of those that are favorable to the point being made.
For example, a popular and entertaining YouTuber who specializes in space-related content and does a great job of balancing the technical level of the presentation with engaging a large fraction of the audience, occasionally makes errors on Twitter; rare as those errors are,1 it’s even more telling that they are not all favorable to the point being made by the popularizer:

There are other popularizers whose errors, usually more numerous, are also disproportionately on the side favoring their point.
For example — and we’ll keep their anonymity to avoid being too mean-spirited — one such “science popularizer” channel on YouTube has a video about the Hyperloop concept with fourteen major errors, all in favor of the position being put forth.2
Incompetence or deceptiveness?
Paraphrasing a famous Ian Fleming Goldfinger quote: one favorable error is happenstance; two is coincidence; fourteen out of fourteen is deliberate deception.
But how can we know? With math, of course!
We’ll call our popularizer Phil, a name chosen at random. What we want is the likelihood ratio (LR) of deliberate deception to accidental errors in Phil’s work, possibly on a single topic (for example, again random, Elon Musk and his companies).
If there are N total errors and F of those are favorable to the argument, the quantity we care about is the probability of observing F given N when Phil is being deceptive divided by the probability of observing F given N when Phil’s errors are equally likely to be favorable or not.
In other words: how much more likely the observed data (N and F; though technically it’s F given N, because we have no distribution for the N) is when Phil is being deceptive than when Phil is just incompetent.

Say Phil is actually being deceptive; shouldn’t F be equal to N, then?
Not necessarily: first because Phil might make unfavorable errors due to incompetence even when trying to be deceptive; and second because Phil might want to muddle the waters with the occasional unfavorable error, to act as a fig leaf on the others (“see, I also make errors in the other direction”).
We could also ask whether we should divide errors into three classes: the ones that help Phil's arguments, the ones that undermine Phil's arguments, and errors that are neutral with respect to the topic.3 But two classes are enough:
Errors that are neutral with respect to the topic are detrimental to Phil's reputation and as such they are errors that work against the argument (because part of the strength of an argument rests with the reputation of the person making it; shouldn't be so, but we live in the real world).
Therefore we can treat errors as binary: either they help the argument or they hurt it, whether they directly undermine the argument or they undermine Phil's credibility.
If there are a total number N of errors and F of those are favorable to the argument, we can compute the likelihood ratio using the same Binomial distribution we have used on a number of other occasions, indicated in the figure above. (The c(N,F) are combinations; they cancel out so we don’t need to look them up on Wikipedia.)
The LR tells us how much more likely it is for our observations to come from a state of the world where Phil is deliberately making a fraction F/N of favorable errors than a state of the world where Phil's errors have an equal chance of helping or detracting from his argument. The following table shows the results for a few small numbers:
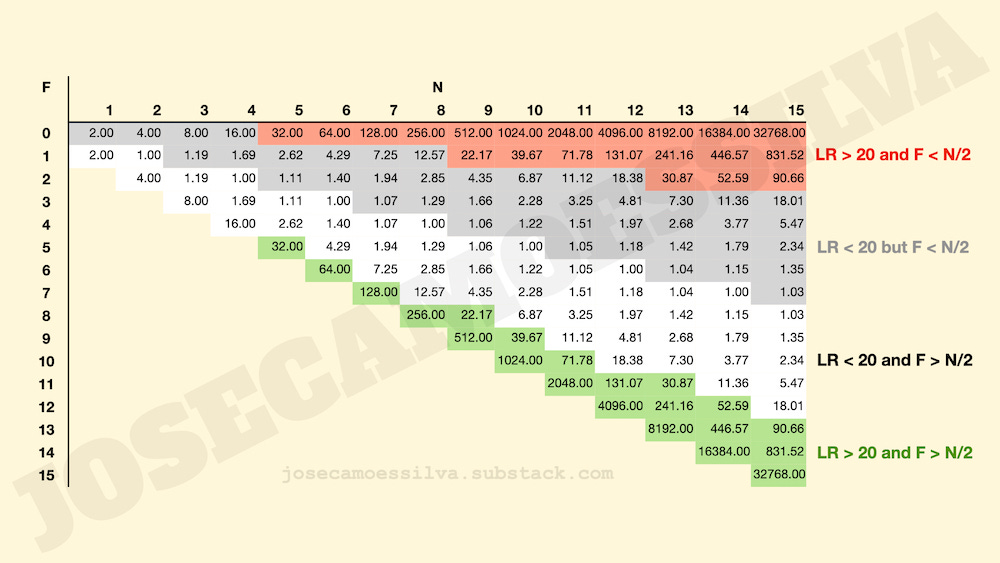
We very arbitrarily choose a ratio of 20 as the cutoff for analysis.4
The cells in the table with a green background are the cases when the number of favorables is larger than half of the total number of errors and the LR indicates it's likely to be a deliberate case.
The cells with white background comprise the indecision area: yes, the errors tend to be favorable, but there’s really little evidence (given our arbitrary threshold of 20) that it’s deliberate.
After all, say there are two errors, both favorable: the likelihood of that happening by random chance is 1/4 (= 1/2 * 1/2), so the LR will be 4, indicating that observing two favorable errors is only four times more likely when Phil is deliberately making two favorable errors (that would be a probability of 1 for the numerator of the LR) than when Phil makes two favorable errors because of incompetence (the 1/4 that goes in the denominator of the LR).
The cells with grey background are interesting: we still have little information to make an assessment of intent, but the errors that undermine the argument are more numerous than the favorable ones, which would suggest incompetence. (Never ascribe to malice what can be satisfactorily explained by incompetence!) We’ll deal with the red-background cells below.
Let us look at our actual case of 14 errors, all favorable: that data is 16,384 times more likely to happen when the popularizer (not our hypothetical Phil, but the real “science popularizer” channel with the Hyperloop video) is being deceptive than by accident.
That 16,348 sounds like a lot.5
What about the reverse case, the red area in the table?
Can someone really be this incompetent?!
Well, the general answer to that question is yes. Whenever we think “no one could possibly be that stupid,” the universe responds with “challenge accepted!”
And wins.
But sometimes we should consider the possibility that what appears to the the most complete incompetence might actually be a form of false flag: enemy action disguised as ineffectual support for a side.6
Say there’s an established technology C to provide essencial good E and investor Tom has a lot of money riding on alternative technology W, which for technical reasons isn't competitive with C. But C has some negative externalities and E is highly regulated, so there’s room for influencing the outcome via politics. (Random names, not intended to represent actual people.)
If Alex is a supporter of technology C but has no technical training, it’s in Tom’s best interest to fund Alex (possibly via a cutout) so that Alex becomes the go-to expert putatively representing the pro-technology C side, because when facing real experts in the field of E who are on the pro-technology W side, Alex will be defeated easily, creating the general impression that technology C is supported by incompetents and technology W is supported by those who know what they're talking about. In other words, Alex’s incompetence works in favor of technology W.
There's also the case when someone like Alex isn’t really on the pro-technology C side, they just pretend to be so that they can undermine that technology from inside. In PR (and espionage and special operations) this is called a false flag operation.
Our likelihood ratio analysis can be used to separate these two cases (incompetence versus false flag), essentially the mirror image of the reasoning we used above: the red area in the table shows cases when it’s more likely that the non-favorable errors (which are the majority in that area) are deliberate than accidental (again using the arbitrary LR = 20 threshold).
Something to ponder when we see people touted as experts undermining their own side by making error after error on media (social or mass).
In the figure the popularizer is the one with withheld identity; the busybody correcting the tweets isn’t popular.
The errors were identified by another YouTube channel, who in a video addressing them made a mistake in their response to one of the errors. (The error was still there, but the response misinterpreted a technical formula that they used to address it.) As a result, the original YouTuber made several videos attacking that one error, filled with personal attacks on the authors, including giving out personal information gleaned from one of those authors’ PhD thesis.
On a side note, none of the criticisms of the Hyperloop concept in the “science popularizer” video had any validity, mostly because they presented what are trivial engineering problems as if they were unsurmountable obstacles. There are valid criticisms of Hyperloop, mostly based on the economics of such a dedicated-infrastructure-intensive project, but those were not the errors being addressed.
Imagine that Phil is comparing two designs for a space launch system, both to be based in Cape Canaveral, but places Cape Canaveral in Michigan. That would be an error that is neutral with respect to the comparison of the flight systems, but shows geographic incompetence and illustrates how a neutral error can undermine one’s argument (how can we trust someone talking about space launch who doesn’t know where the most famous space launch base is?).
It’s arbitrary, but for frequentists that have a p-value fetish, it’s roughly equivalent to a “p<0.05” or “95% statistical significance.” The difference between LR and either of those two statements is that a likelihood ratio actually means something.
Note also that LR = 20 does not mean that the probability that Phil is being deceptive is twenty-fold that of Phil being merely incompetent. For that we’d need prior probabilities, since what we have in the table above is
Pr(data|deceptive)/Pr(data|incompetent),
not — what the statement after the boldface “not” above translates to —
Pr(deceptive|data)/Pr(incompetent|data).
Shameless self-promotion: People interested in learning more about the meaning of statistical testing (inasmuch as there’s any) and Bayesian reasoning (of which there’s a lot), can find more in my book, which has two interludes, one about how statistics are weird and another about Bayesian thinking. Get your free sample (which alas doesn't include either of the interludes) here:
DATA to INFORMATION to DECISION and ten things people get wrong about numbers, data, and models
(The book is free with Kindle Unlimited.)
We could make an argument here that being caught making so many errors would put “science popularizer” in the false-flag category. But the issue is the being caught part. First, most people don't catch technical errors, especially when they feed into their biases; second, in the era of social media and algorithmic filtering, being technically right is unimportant in determining the reach and engagement of a popularizer, and the audience rarely cares; and third, “science popularizer” has shown itself to be impervious to technical arguments and to resort to base tactics, as illustrated by footnote 2 above.
In politics (and some milder versions of public relations) this is also called “Controlled Opposition,” but as anyone who’s ever hung out with management consultants will have noticed, they (well, we) love to use military or spy jargon.